10 Critical Questions You Must Answer Before Implementing Delta Live Tables (DLT/SDP)
The 2025 Strategic Guide for Data Leaders and Architects
Between 2023 and 2025, Databricks Delta Live Tables (DLT) transitioned from a promising feature to an enterprise-grade orchestration standard. With the introduction of DLT Serverless to reduce operational overhead, deep integration with Unity Catalog for governance, and rigorous deployment standards via Databricks Asset Bundles (DABs), the platform has effectively neutralized its early adoption friction.
For a CIO or CTO, the value proposition is clear: DLT promises to replace brittle, custom-coded pipelines with declarative, self-healing infrastructure. It is designed to lower maintenance costs and accelerate data delivery.
However, there is a caveat that vendors rarely highlight. DLT is not a magic fix for broken processes; it is just an amplifier.
If your data governance is mature and your architecture is decoupled, DLT acts as a force multiplier for velocity and reliability.
If your organization suffers from ambiguous data ownership, "spaghetti" dependencies, or a lack of engineering discipline, DLT will not solve these problems. Instead, it will expose them—often resulting in spiraling cloud costs and stalled projects.
Implementing DLT is not merely a technical migration; it is a shift in your data operating model.
This guide provides the strategic architectural perspective required for 2025. We move beyond the "how-to" to ask the "should-we." Before you commit your roadmap (and budget) to DLT, you must answer these ten critical questions to ensure your organization is ready to harness its power without falling into the complexity trap.
Note:
While we use the established industry term DLT throughout this guide, be aware that this technology is evolving under the Databricks Lakeflow umbrella and will soon be formalized as Spark Declarative Pipelines (SDP). The naming conventions are shifting, but the strategic imperatives outlined here remain unchanged.

Executive Summary
10 Critical Questions for DLT Implementation
| Navigation Area | The Section Question (Key Issue) | Strategic Verdict & Recommendation | Business Risk (If Ignored) | |
|---|---|---|---|---|
| 1 | Ingestion Costs | Do Your Source Systems Support True Incremental Ingestion or CDC? (CDC vs. Full Refresh) |
Fix the Source or Pay the Price. DLT can simulate CDC (via APPLY CHANGES INTO), but it is computationally expensive. Prefer native CDC logs. |
Runaway Costs: Paying premium compute to "brute force" recalculate full historical datasets every day. |
| 2 | Code Discipline | Is Your Transformation Logic Compatible with a Declarative Engine? (Imperative vs. Declarative) |
Avoid "String Soup." Use Python for metaprogramming (the skeleton), but keep business logic in clean SQL or native DataFrame API. |
Maintainability Trap: Creating "Black Box" code that is impossible to debug or unit test. |
| 3 | DevOps / CI/CD | Do You Have a Strategy for Multi-User Development and CI/CD? (DABs & CI/CD) |
DABs are Mandatory. Move from "UI Clicking" to Infrastructure-as-Code. You need isolated environments for every developer. |
Integration Hell: One developer's error blocks the entire team; inability to deploy safely to Production. |
| 4 | SLA / Latency | Are Your SLA Requirements Compatible with Micro-Batching? (Real-Time vs. Micro-Batch) |
Don't Promise Real-Time. DLT has a physical latency floor (~10–15s). For sub-second needs, use Flink/Kafka. |
Small File Problem: Forcing low latency degrades performance and explodes cloud storage API costs. |
| 5 | FinOps | Is Your FinOps Model Ready for the "Black Box" of Abstraction? (Streaming Tables vs. Materialized Views) |
Default to Streaming Tables. Use Materialized Views sparingly. In Serverless mode, MVs can trigger expensive full re-computes. |
Budget Shock: Unoptimized MVs auto-scaling to max capacity to rewrite history, draining the budget. |
| 6 | Data Quality | How Will You Handle the "Quality vs. Availability" Trade-off? (Quarantine Pattern) |
Use the Quarantine Pattern. Never use EXPECT OR FAIL on ingestion. Route bad data to error tables instead of stopping the pipeline. |
Self-Inflicted DoS: A single typo from a vendor shuts down enterprise reporting at 3:00 AM. |
| 7 | Team Structure | Do You Have the Engineering Maturity to Support a Hybrid Team? (Python/SQL Hybrid Model) |
Adopt a Hybrid Model. "Platform Engineers" (Python) build the factory; "Analysts" (SQL) build the product. SQL alone is not enough. |
Technical Debt: Analysts building "technically functional but economically ruinous" pipelines. |
| 8 | Vendor Lock-in | Are You Willing to Trade Code Portability for Operational Velocity? (Vendor Lock-in) |
The Factory Strategy. Accept that Code is locked (requires rewrite to exit), but Data is free (via Delta UniForm). |
The "Rewrite Tax": The high cost of rewriting orchestration logic if moving to Airflow/Glue later. |
| 9 | Architecture | Is Your Medallion Architecture Defined, or Just Implied? (Unity Catalog & Governance) |
Unity Catalog is Standard. Without UC, you lack lineage. Enforce strict Bronze/Silver/Gold layers in code reviews. |
High-Speed Mess: DLT accelerates data delivery, but also accelerates the propagation of bad logic. |
| 10 | Maintenance | Can Your Team Keep Up with Fast-Evolving Platform Features? (Platform Maintenance) |
Assign a Platform Owner. Features like Liquid Clustering make old code obsolete. Dedicate 10% time to refactoring. |
Silent Obsolescence: Paying "2023 prices" for performance that could be 40% cheaper with modern features. |
1. Do Your Source Systems Support True Incremental Ingestion or CDC?
Databricks Delta Live Tables (DLT) is, at its core, a streaming engine. Even when running in "Triggered" (batch) mode, its internal architecture creates stateful checkpoints designed to process data row-by-row or micro-batch-by-micro-batch. Its entire economic model is predicated on the assumption that it is processing deltas—only the data that has changed since the last run.
The Architectural Disconnect: The "Computationally Expensive Magic." If your upstream operational systems (ERPs, CRMs, Legacy Databases) cannot provide Change Data Capture (CDC) logs or reliable high-water mark timestamps, you face a dilemma.
The Capability: DLT can handle this via the APPLY CHANGES INTO command. This feature acts as a "magic wand," allowing DLT to ingest a full daily snapshot, compare it against the target state, and automatically handle SCD Type 1 or Type 2 updates.
The Cost: While DLT can logically derive the delta, it cannot cheat physics. To find the changes in a full snapshot, the engine must ingest, hash, and compare the entire dataset against the existing table every single day. You are effectively paying for a "Brute Force" calculation of CDC.
The Business Impact: Operational vs. Runaway Costs For the C-Suite, this is a direct question of TCO (Total Cost of Ownership):
With True CDC: DLT scales up for minutes, processes the 5% of data that changed, and shuts down. Costs are linear and predictable.
With Simulated CDC (Snapshot Diffing): DLT must auto-scale to process 100% of the volume just to find the 5% that changed. You are paying a premium for the engine to do the work that the source system should have done. Routine jobs can turn into compute marathons, blocking critical SLAs.
The Verdict: If your data strategy relies heavily on TRUNCATE AND LOAD or full snapshots, DLT is not necessarily the "wrong" tool, but it is the expensive tool.
Accept the Premium: You can use DLT for its convenience and declarative SCD logic (APPLY CHANGES INTO), but accept that you will pay a "Computational Tax" for deriving deltas from snapshots.
Fix the Source: The most cost-effective path is always to fix the ingestion pattern to provide true incremental feeds.
2. Is Your Transformation Logic Compatible with a Declarative Engine?
Adopting DLT requires a fundamental shift from imperative scripting (telling the computer how to do it) to a declarative, static mindset (telling the computer what you want). The engine must map the entire lineage and dependency tree—the Directed Acyclic Graph (DAG)—before it processes a single row.
The Hard Constraint: Static Topology (No Runtime Surprises) DLT requires the entire dependency graph (DAG) to be compiled before a single row is processed. This creates a rigid distinction between filtering data and defining infrastructure.
· Allowed (Data Flow): Routing rows to pre-defined destinations (e.g., sending region = 'US' data to the existing US_Silver table).
· Forbidden (Control Flow): Changing the pipeline structure based on data content (e.g., trying to dynamically spawn a new table just because a new 'Region' code appeared in the stream).
The 2025 Python Update: Metaprogramming vs. Magic The mature Python DLT API now allows for powerful Metaprogramming. This solves scalability, not runtime rigidity.
What it does: You can use Python "Factory Patterns" to read a config file and generate 50 distinct pipeline paths at startup. This is excellent for DRY (Don't Repeat Yourself) engineering.
What it doesn't do: It does not allow the pipeline to reinvent itself during execution. The Python code runs once to build the DAG; the DAG then runs the data.
The Maintenance Trap: The "String Soup" Anti-Pattern A common mistake in 2025 is misusing the Python API to embed massive, complex SQL logic directly inside Python strings.
· The Problem: This destroys readability, breaks syntax highlighting, and makes unit testing impossible. It creates a "black box" where logic is trapped in text blocks that the Python compiler cannot validate.
· The Right Way: Do not treat Python merely as a wrapper for SQL strings.
o For the "Platform Layer" (Orchestration): Use Python to read configurations and generate pipelines dynamically (e.g., looping through a list of tables).
o For the "Business Layer" (Logic): Use external .sql files for standard transformations. Switch to the native PySpark DataFrame API only when SQL becomes unwieldy (e.g., handling complex nested JSON, heavy struct manipulation, or logic that requires unit tests).
The Verdict: Metaprogramming is a Force Multiplier, but Readability is Paramount
A pipeline that "generates itself" is powerful for scale but dangerous for maintenance. If you are embedding 50 lines of SQL inside a Python f-string, you are creating a "black box" that is impossible to test or debug.
The Golden Rule: Use Python to manage the structure (loops, configs, DAG generation) but keep the logic explicit.
· Simple Logic: Keep it in clean, external .sql files.
· Complex Logic: Use the native PySpark DataFrame API.
· Never: Paste massive SQL blocks into Python strings. Complexity is the enemy of reliability.
Strategic Rule:Match the language to the complexity. If your team lacks strong software engineering discipline (CI/CD, Unit Testing), stick to standard SQL to avoid creating unmaintainable technical debt. However, for advanced teams, Python is not just a shell—it is a scalpel for logic that SQL cannot handle elegantly.
3. Do You Have a Strategy for Multi-User Development and CI/CD?
Early DLT implementations notoriously suffered from "Integration Hell." Because developers often shared a single pipeline to save on cluster startup times, a broken line of code from one engineer would halt the entire team. Testing a simple change required slow, full refreshes, killing velocity.
The Enabler: Databricks Asset Bundles (DABs) DABs are the engineering standard that shifts DLT from "Notebook Hacking" to a structured development lifecycle. While not a magic fix for all complexity, they provide the necessary framework to treat your pipeline definition as Infrastructure as Code (IaC).
· Isolation via Development Targets: Instead of claiming full "Ephemeral Environments" out of the box, DABs allow developers to deploy private pipeline instances to their own schemas (leveraging DLT’s support for publishing to multiple schemas). This solves the concurrency problem: developers no longer block each other, and changes can be tested in isolation before merging.
· Structured CI/CD: Configuration lives in Git (YAML), enabling a safe path for promotion from Dev → Staging → Prod. Production pipelines become immutable artifacts, never touched by human hands.
The Barrier: Git Maturity This is a hard skill requirement. DABs replace "UI clicking" with CLI commands, YAML configuration, and Pull Requests. If your team is not comfortable with Git flow, DABs will feel like an obstacle rather than an enabler.
The Verdict: Without DABs (or a similar IaC approach), DLT scales poorly in a team environment. DABs are not a remedy for bad architecture, but they are the critical component that turns a prototype tool into an enterprise platform.
4. Are Your SLA Requirements Compatible with Micro-Batching?
One of the most common friction points in DLT adoption is semantic: Stakeholders hear "Live Tables" and assume "Sub-Second Real-Time."
The Architectural Reality: The "ACID Penalty" DLT is built on Spark Structured Streaming, which uses a micro-batch architecture. It processes data in small chunks, committing ACID transaction logs to Delta Lake at every step.
The Latency Floor: Because of this transaction overhead (writing parquet files to object storage + updating transaction logs), DLT has a hard physical limit. Even with infinite compute, achieving consistent end-to-end latency below 10–15 seconds is technically difficult and economically ruinous.
The Trap: If you force DLT to run faster than its architectural floor, you generate the "Small File Problem"—millions of tiny files that degrade read performance and explode cloud storage API costs.
The Serverless Nuance: Startup Time vs. Transit Time DLT Serverless is a major win for SLAs, but it is critical to understand what it fixes:
It Fixes Startup Time: Resources are available instantly (eliminating the 7-minute cluster spin-up lag).
It Does NOT Fix Transit Time: Once the job starts, data still moves at the speed of micro-batches.
The Verdict: Map SLAs to the Right Engine
Sub-Second (< 1s): Use Apache Flink or Kafka Streams. DLT cannot compete here; do not try to force it.
Near Real-Time (10s – 15m): Use DLT Continuous Mode. This is the sweet spot for operational dashboards.
Batch (15m+): Use DLT Triggered Mode. This is the most cost-efficient method for standard reporting.
Rule of Thumb: Do not promise "Real-Time" to the business when you are delivering "Near Real-Time." The difference is measured in milliseconds, but the architectural cost is measured in millions.

"Don't use a cannon to kill a fly." — Confucius
5. Is Your FinOps Model Ready for the "Black Box" of Abstraction?
One of DLT's main selling points is that it abstracts away cluster management, automatically handling autoscaling and retries. However, this convenience creates a "Black Box" effect where cost behavior becomes opaque. In the old world, you paid for uptime (how long the cluster ran). In the DLT world, you are paying for complexity (how hard the engine has to work).
The Silent Cost Killer: Streaming Tables (ST) vs. Materialized Views (MV) The most critical architectural decision in DLT is not the cluster size, but the table type. They look similar in code, but their financial profiles are radically different.
Streaming Tables (STs):
Behavior: Append-only, strictly incremental.
Cost Profile: Linear and predictable. You pay only to process new rows.
Role: The workhorse for Bronze and Silver layers (Ingestion, Cleaning, Parsing).
Materialized Views (MVs):
Behavior: State-aware and declarative. The engine guarantees the result, not the process. If DLT cannot mathematically prove how to apply a delta (e.g., due to complex non-deterministic joins), it defaults to a Full Recompute.
The Risk: A junior engineer changing one line of logic in a large MV can inadvertently trigger a daily re-read of 5 years of history.
Cost Profile: Volatile and potentially explosive.
The Serverless Multiplier: The Price of Laziness DLT Serverless simplifies operations but introduces a premium DBU pricing model. This creates a dangerous multiplier effect for bad code:
Scenario: An unoptimized Materialized View performs a full refresh daily.
Old World: It ran on standard compute. Slow, expensive, but manageable.
New World (Serverless): It runs on Premium Serverless compute, autoscaling to maximum instantly to finish the job fast.
The Result: Inefficiency × Premium Pricing = Budget Shock.
A single poorly designed MV in your Silver layer can consume more budget in a week than your entire Bronze layer consumes in a quarter.
The Verdict: FinOps Must Be Baked into the Code You cannot manage DLT costs via dashboards alone; you must manage them via architecture.
Default to Streaming Tables: Force teams to use STs for 90% of the pipeline. If it can be a stream, it must be a stream.
Gatekeep Materialized Views: Treat MVs as a "Luxury Resource" reserved for small, highly aggregated Gold tables where data consistency is worth the premium.
Monitor the "Recompute" Metric: If a large table is fully refreshing daily, treat it as a P1 bug, not a feature.
| Feature | Streaming Tables (ST) | Materialized Views (MV) |
|---|---|---|
| Behavior | Append-only, strictly incremental. | State-aware and declarative. Engine guarantees results, not process. |
| Cost Profile | Linear & Predictable. Pay only for processed new rows. | Volatile & Explosive. High risk of full recomputes. |
| Processing Logic | Strictly incremental (New rows only). | May trigger a Full Recompute if engine cannot prove delta logic. |
| Primary Role | Workhorse for Bronze & Silver layers (Ingestion/Cleaning). | Luxury Resource for small, highly aggregated Gold tables. |
| FinOps Strategy | Default Choice: "If it can be a stream, it must be a stream." | Gatekept Resource: Reserved for specific data consistency needs. |
| Serverless Risk | Standard managed compute costs. | Budget Shock: Inefficiency × Premium Serverless Pricing. |
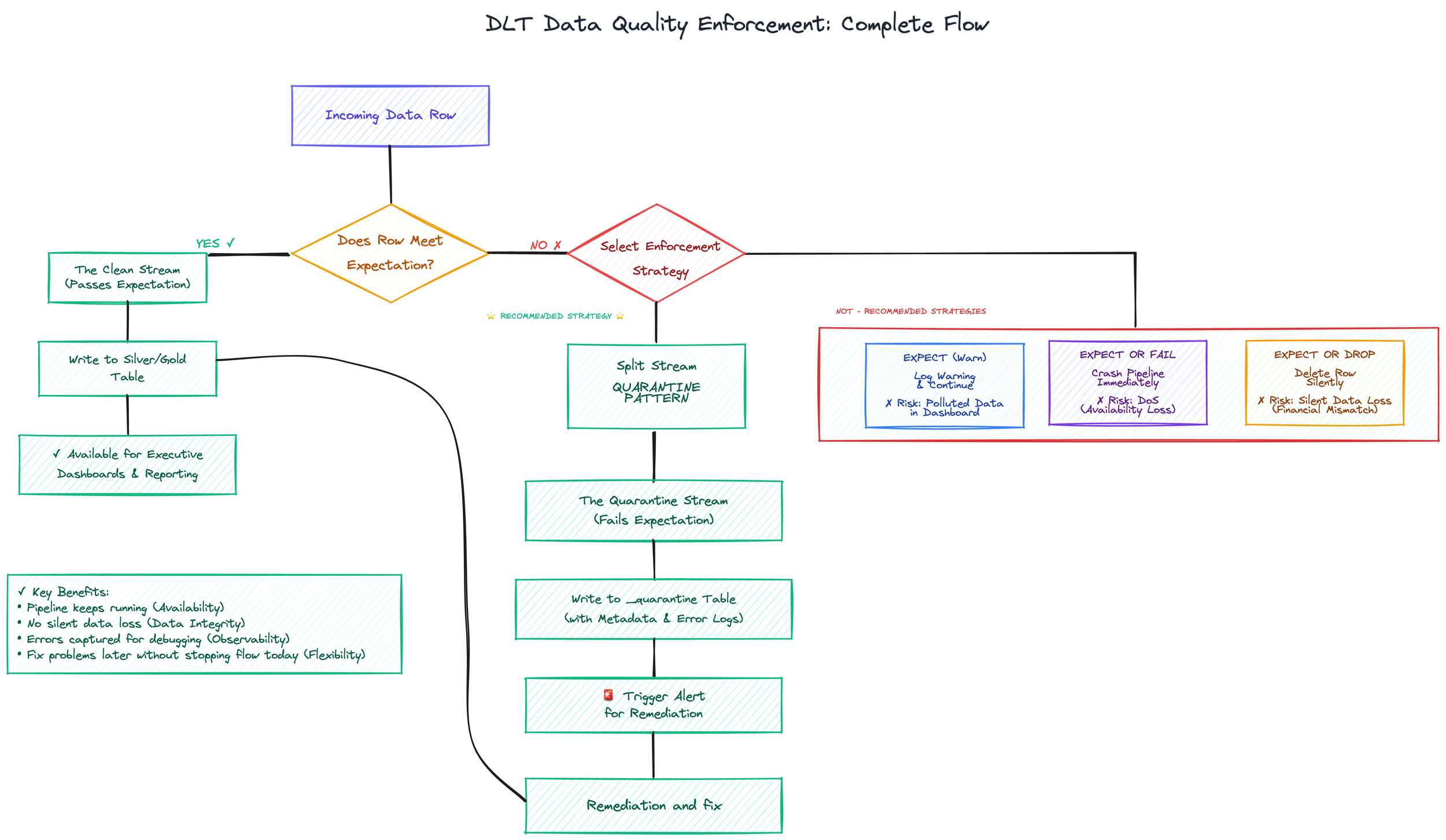
6. How Will You Handle the "Quality vs. Availability" Trade-off?
DLT elevates Data Quality from an afterthought to a first-class syntax via Expectations (CONSTRAINT). You can define rules like Sales > 0 directly in the table definition. However, this feature introduces a dangerous architectural dilemma. When bad data arrives (and it will arrive), you must decide—row by row—what is more important: Data Accuracy or Pipeline Availability?.
The Three Dangerous Tiers of Enforcement:
EXPECT (Warn): The pipeline continues, and the error is logged.
The Risk: Alert Fatigue. If nobody monitors the logs daily (and they won't), you are knowingly feeding polluted data into executive dashboards.
EXPECT OR DROP (Filter): The pipeline continues, but the bad row is silently deleted.
The Risk: Silent Data Loss. In financial or regulatory contexts, this is dangerous. You might be "dropping" revenue. It is difficult to explain to a CFO why the data warehouse shows lower sales than the bank deposits.
EXPECT OR FAIL (Stop): The pipeline crashes immediately upon encountering bad data.
The Risk: Self-Inflicted Denial of Service. A single typo in a CSV file from a third-party vendor can bring down your entire enterprise reporting platform at 3:00 AM.
The Solution: The "Quarantine" Pattern Modern DLT architectures reject the binary choice of "Drop" or "Fail." Instead, they utilize a Quarantine Pattern (often called Error Tables or Dead Letter Queues). Instead of destroying the row or stopping the engine, you split the stream:
Clean Stream: Passes the expectation and flows to the Silver/Gold table for reporting.
Quarantine Stream: Fails the expectation and is written to a separate _quarantine table with metadata explaining why it failed and when.
The "Black Box" Reality: Observability vs. Debuggability While DLT pushes high-level quality statistics directly to Unity Catalog creating a nice "Health Dashboard" for governance teams, it introduces a significant Debuggability Gap for engineers.
The Abstraction Trap: DLT abstracts away the "guts" of Spark. When a pipeline fails with a generic error like stream initialization failed, finding the root cause is significantly harder than in standard Databricks Jobs. You do not get the same clean visibility into driver logs or stack traces.
The Event Log Nightmare: The source of truth for DLT is the system event_log. However, this is stored as complex, nested JSON data.
The Hidden Cost: To monitor DLT effectively in real-time, you often need to build a separate pipeline just to parse the logs of your main pipeline. Without this, you are flying blind when system-level (not data-level) errors occur.
The Verdict:
Never use EXPECT OR FAIL on Bronze/Ingestion layers. You cannot control external vendors; do not let their mistakes stop your processing.
Capture, Don't Drop. Avoid EXPECT OR DROP for critical financial data. Use Quarantine tables so you can fix errors later without stopping the flow today.
Plan for Deep Observability. Do not rely solely on the Unity Catalog UI. Be prepared to implement a custom parser for the event_log to catch system failures that the high-level dashboard misses. Availability is king, but debuggability is what saves your weekend.
7. Do You Have the Engineering Maturity to Support a Hybrid Team?
There is a dangerous market misconception: "DLT allows us to write standard SQL, so we don't need expensive Data Engineers”. This is a critical operational error.
While DLT simplifies the syntax (the code you write), it complicates the semantics (what happens under the hood). DLT is an abstraction over Spark Structured Streaming. When it works, it feels like magic. When it breaks, it breaks like a complex distributed system, not like a stored procedure.
The "Streaming Mindset" Gap Migrating from legacy ETL (SSIS, Informatica) is not a tool swap; it is a paradigm shift.
Old Way: Truncate & Load.
New Way: Stateful Streaming. Your team must master checkpoints, watermarks, and incremental design.
The Reality: If your team treats DLT like a batch sequencer, they will build pipelines that are technically functional but economically ruinous.
The Solution: The "Polyglot" Operating Model You cannot fire your Engineers, but you shouldn't strictly fence off Analysts from the codebase. The 2025 standard is a Collaborative Division of Labor:
The "Platform Engineers" (Python/Spark): They build the "Factory." They handle the complexity of Ingestion (Bronze), CI/CD (DABs), error handling, and reusable Python libraries for complex transformations.
The "Analytics Engineers" (SQL/Python): They define the "Product." While they primarily use SQL for readability in Gold layers, they are not banned from Python. They use the tool that best solves the business problem.
The Verdict: Assign Roles by Competency, Not Just Title
The "Anchor" Hire: You need at least one Senior Data Engineer who deeply understands Spark Structured Streaming. You need a pilot to debug the engine when it stalls, not just passengers who can write SELECT statements.
Layer Strategy:
Bronze (Ingestion): Predominantly Python (Standardized, automated, handles varied formats).
Silver/Gold (Business Logic): SQL by default, Python by necessity. Prefer SQL for logic that needs to be verified by business users, but do not hesitate to use Python (PySpark) for complex deduplication, sessionization, or advanced calculations that would require "SQL gymnastics".
The Goal: A pipeline where the implementation language is chosen based on maintainability and testability, not dogma.
8. Are You Willing to Trade Code Portability for Operational Velocity – vendor lock-in dilemma?
In every architecture review, the "Exit Strategy" question arises.
The Hard Truth: DLT is proprietary. Your code will not run natively on AWS Glue or Snowflake. By adopting DLT, you are explicitly trading Code Portability for Operational Velocity (typically 30–50% faster delivery).
The 2025 Safety Net: Delta UniForm (Data is Free, Code is Not) "Vendor Lock-in" used to mean trapped data. No longer. With Delta UniForm, your data resides in open object storage (S3/ADLS) and is readable by Snowflake, BigQuery, or Athena as native Iceberg tables.
Data is Portable: You can point a new engine at your data tomorrow.
Compute is Trapped: Your pipelines are tied to the Databricks engine via specific syntax (e.g., @dlt.table decorators).
The Re-platforming Reality: The "Rewrite" Tax The author must not underestimate the cost of the exit. DLT is not standard PySpark; it is a framework wrapping Spark.
The Problem: You cannot simply "lift and shift" DLT code to another platform.
The Cost: Leaving Databricks does not mean "taking your code and going elsewhere"; it means rewriting your entire ETL layer from scratch (e.g., porting logic to standard Airflow + Spark Submit). The logic is entangled with the proprietary orchestration.
The Alternative: The "DIY Tax" To avoid this lock-in, you must build your own orchestration framework (Airflow + Spark). You avoid the license cost and keep the code portable, but you pay the "Engineering Tax" of maintaining custom infrastructure and writing boilerplate code.
The Verdict: The Factory Strategy (With Eyes Open) Treat DLT as a high-efficiency "Factory."
If you ever decide to leave Databricks, you keep the inventory (the data via UniForm), but you must be prepared to abandon the machinery (the code).
The "Factory Strategy" is essentially a business decision to accept that the code is a sunk cost in exchange for speed today. Do not pretend the exit cost is zero—it is a full rewrite. In the modern cloud, that is often an acceptable risk, provided you are honest about it.
9. Is Your Medallion Architecture Defined, or Just Implied?
There is a saying in modern data engineering: "DLT enforces execution order, not logical sanity." DLT will happily execute a spaghetti architecture where Gold tables read from Bronze, and circular dependencies lurk in the shadows. The engine builds the DAG you gave it, not the one you should have.
The "Magnifier" Effect If your current architecture is chaotic—with inconsistent definitions of "Silver" or "God Tables" that do everything—DLT will not fix it. It will magnify the chaos.
The Risk: Because DLT runs continuously, a structural flaw (like bad join logic) propagates corrupt data to the entire enterprise 100x faster than a legacy nightly batch job.
The Requirement: You need rigid, code-enforced definitions:
Bronze: Raw, append-only, history-preserving.
Silver: Cleaned, deduped, enriched (The "Truth").
Gold: Aggregated, business-ready (The "Metric").
The Strategic Partner: Unity Catalog (UC) In the early days, running DLT without Unity Catalog was standard. In 2025, it is the Gold Standard, but it comes with nuance.
The Legacy Reality: Many large enterprises still operate stable, massive environments based on Hive Metastore and legacy ACLs. Migrating these to Unity Catalog is a complex, high-risk infrastructure project, not a simple "on/off" switch.
The Value Gap: However, running DLT without UC leaves significant value on the table. Without UC, you lose automatic Column-Level Lineage and centralized Data Discovery. You are using the engine, but missing the platform governance.
The Verdict:
Greenfield = UC Required: For new implementations, starting without Unity Catalog is creating immediate technical debt. Do not launch new platforms on Hive Metastore.
Brownfield = Plan the Migration: If you are bound to a legacy Hive Metastore, you can still deploy DLT, but accept that you will lack lineage visibility until you migrate. Do not let the complexity of a UC migration block your DLT adoption, but roadmap it as a priority.
The "Clean Room" Rule: If you are migrating legacy spaghetti code, do not "lift and shift" it into DLT. Refactor it into a clean Medallion structure first. Otherwise, you will simply create a "High-Speed Mess."
10. Can Your Team Keep Up with Fast-Evolving Platform Features?
Databricks does not operate on a traditional "Major Version" release cycle (v1.0 → v2.0). It operates on a continuous delivery model where the architecture you designed six months ago might already be an "anti-pattern" today.
The "Best Practice" Shelf Life The shelf life of a "Best Practice" in the DLT ecosystem is roughly 9 to 12 months.
Example (Partitioning): In 2023, you spent weeks tuning PARTITIONED BY columns and Z-Ordering strategies.
The Shift: In 2025, Liquid Clustering rendered that effort obsolete. If you are still manually partitioning DLT tables, you are actively writing legacy code that is slower and more expensive than the default.
The Risk: Silent Obsolescence The danger isn't that your pipeline will break. The danger is that it will continue to work, but inefficiently. We call this "Silent Obsolescence." You end up paying "2023 prices" for performance that could be 40% cheaper with modern features (like Photon or Serverless), simply because your team didn't read the release notes.
The "LakeFlow" Evolution The rebranding and evolution of ingestion patterns into Databricks LakeFlow demonstrates this velocity. Features like evolutionary schema inference or variant data types appear overnight. If your team treats DLT as a "Set and Forget" appliance, you will miss these optimizations. You will be running a steam engine on an electric grid.
2025/2026 Critical Update: The End of "DLT" As explicit proof of this velocity, the "Delta Live Tables" brand is currently transitioning into Lakeflow Spark Declarative Pipelines (SDP).
· The Shift: This aligns the proprietary engine with the open Apache Spark Declarative Pipelines standard.
· The Impact: The syntax is evolving from proprietary @dlt decorators to native pyspark.pipelines definitions. If you aren't tracking these changes, your "new" code might be legacy on Day 1.
The Verdict: You Need a Platform Owner
Stop "Set and Forget": DLT is not a database; it is a managed service that demands active curation.
The "10% Tax": Allocate 10% of your Lead Engineer's time strictly for R&D and reading release notes. If they are 100% utilized on ticket delivery, your platform is rotting.
Refactor Cycles: Plan for a "Platform Refactor" sprint every 6 months just to adopt new efficiency features (e.g., switching to Liquid Clustering, enabling new Serverless toggles).
11. Do I really need to do it alone…?
Short answer - no, you don’t. In Exerizon we have a vast experience in DLT & Databricks - we are ready to support you with any challenge you may have. Just leave you contact details, and we’ll take it from here.